



LangChain’s Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
Harness Engineering Techniques Propel LangChain’s AI Coding Agent from Mediocre to Exceptional Performance
🚀 Why did LangChain’s AI coding agent leap from #30 to #5 on Terminal Bench 2.0? The secret isn’t in the model; it’s all about the harness engineering! Discover how self-verification loops and clever middleware can supercharge your AI’s performance. Read the full story!
Summary: LangChain’s coding agent improved from 52.8% to 66.5% on Terminal Bench 2.0, moving from the Top 30 to the Top 5, through harness engineering techniques without changing the model. Key strategies included self-verification loops, loop detection middleware, and context engineering, which optimized agent performance by refining the surrounding infrastructure rather than the model itself. The article emphasizes the importance of verification, strategic reasoning allocation, and proactive context delivery for enhancing AI coding agents.
Part 6 of the LangChain Deep Agents Series
Your AI coding agent has the same model as the competition. Same weights, same training data, same capabilities. So why does it rank #30 while others sit comfortably in the Top 5?
LangChain asked that question and found an answer that surprised even them. Their coding agent, deepagents-cli, jumped from 52.8% to 66.5% on Terminal Bench 2.0, vaulting from outside the Top 30 into the Top 5. The model never changed. Not once. Every percentage point of that 13.7-point improvement came from what they call harness engineering: the systematic optimization of everything around the model.
TLDR: Our coding agent went from Top 30 to Top 5 on Terminal Bench 2.0. We only changed the harness. Here’s our approach to harness engineering (teaser: self-verification & tracing help a lot). — LangChain Blog
If you have been following this series, harness engineering is where all the concepts we have covered come together. The middleware patterns from Part 2, the context engineering from Part 5, the architectural principles from Part 1. This article is the proof point. Here is what happens when you apply them to a real benchmark competition.
This is the story of how LangChain did it. More importantly, it is a playbook of patterns you can apply to your own agents today.
What Terminal Bench 2.0 Actually Measures
Before we dig into the engineering, let’s understand the playing field.
Terminal Bench 2.0 is a benchmark developed by Stanford University and the Laude Institute. It evaluates AI coding agents on the kind of work that actually matters: long-horizon, complex terminal tasks in realistic environments. Unlike synthetic benchmarks that test isolated coding puzzles, Terminal Bench 2.0 presents agents with 89 Dockerized tasks across 10 technical domains, including software engineering, machine learning, security analysis, data science, and biology.
Each task runs in a containerized environment with pytest-based verification. There is no ambiguity about whether the agent succeeded or failed. And the tasks are genuinely hard. They require agents to maintain context across dozens of tool calls, navigate unfamiliar codebases, and solve problems that demand both technical knowledge and creative thinking. One task asks agents to reverse-engineer C programs from images. Another involves managing complex git merge conflicts across multiple branches. Some extended tasks, like COBOL modernization, require 100+ tool calls over roughly 10 minutes.
Here is what the current leaderboard looks like as of Febuary 2026:
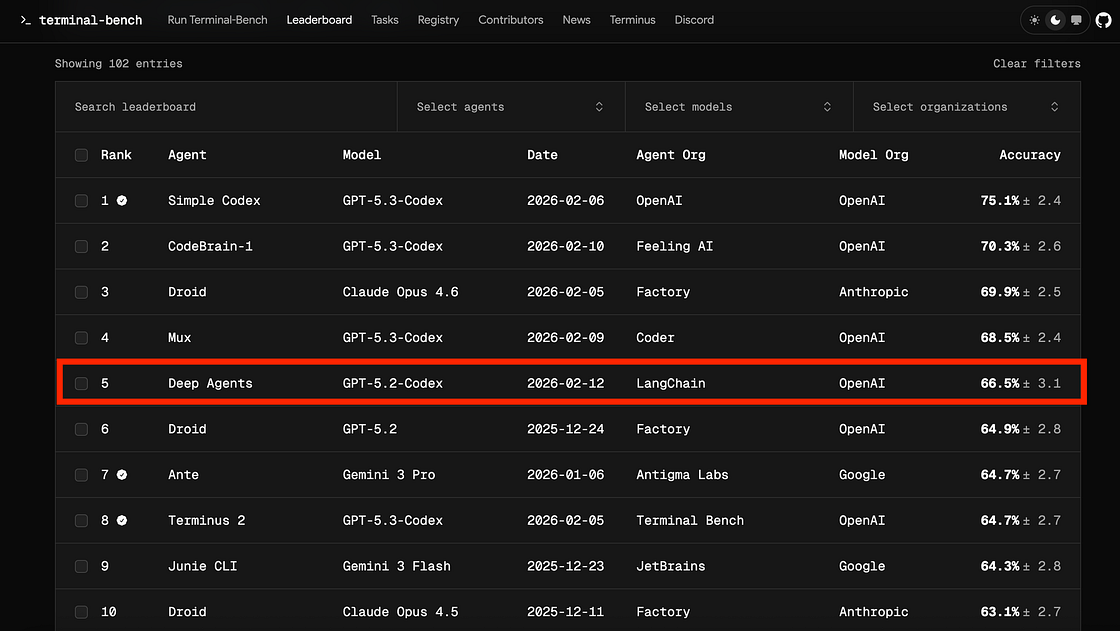
Rank — Agent — Model — Accuracy
- 1 — Simple Codex — GPT‑5.3‑Codex — 75.1% ± 2.4
- 2 — CodeBrain‑1 — GPT‑5.3‑Codex — 70.3% ± 2.6
- 3 — Droid — Claude Opus 4.6–69.9% ± 2.5
- 4 — Mux — GPT‑5.3‑Codex — 68.5% ± 2.4
- 5 — Deep Agents — GPT‑5.2‑Codex — 66.5% ± 3.1
- 6 — Droid — GPT‑5.2–64.9% ± 2.8
- 7 — Ante — Gemini 3 Pro — 64.7% ± 2.7
- 8 — Terminus 2 — GPT‑5.3‑Codex — 64.7% ± 2.7
- 9 — Junie CLI — Gemini 3 Flash — 64.3% ± 2.8
- 10 — Droid — Claude Opus 4.5–63.1% ± 2.7
Notice something? Deep Agents appears in 5th place alongside several bespoke coding agents built around the same frontier models. At that time, GPT‑5.3‑Codex–based agents (Simple Codex, CodeBrain‑1, Mux, Terminus 2) and Claude‑ and Gemini‑based agents (Droid with Claude Opus 4.6/4.5, Ante with Gemini 3 Pro, Junie CLI with Gemini 3 Flash) all cluster in the mid‑60s to mid‑70s on Terminal‑Bench 2.0. Deep Agents, wrapping GPT‑5.2‑Codex, lands at 66.5% — within a few points of the best published GPT‑5.3‑Codex and Claude Opus 4.6 agents in that February 2026 snapshot, underscoring how much the harness can narrow the gap between underlying models. To highlight this further, Terminus 2 scored in 8th place and it is using a new and improved version of GPT Codex. The engineering harness can matter more than the model.
Terminal‑Bench 2.0: LangChain DeepAgent scored above Codex, Claude Code, OpenCode, and Gemini CLI. Copilot was not on the list. LangChain DeepAgent is pretty amazing.
Key point: This leaderboard tells a story that every AI engineer needs to hear: if you are spending all your time evaluating models and none building infrastructure, you are optimizing the wrong thing.
Agent = Model + Harness
This brings us to the core insight that drove LangChain DeepAgent’s improvement.
LangChain frames the relationship simply: an agent equals a model plus a harness. The harness is every piece of code, configuration, and execution logic that is not the model itself. System prompts, tools, middleware, execution flows, sandboxes, filesystems, and memory management all belong to the harness.

The harness serves four distinct functions:
- Constrain: Limit what the agent can do through sandboxes, hooks, command allow-lists, and network isolation. This prevents the agent from going off the rails in ways that waste time or cause harm.
- Inform: Deliver the context the agent needs, including environment mapping, task specifications, and codebase structure. Anything the agent cannot access in-context does not exist to it.
- Verify: Check the agent’s work through testing and validation. This is where most performance gains come from.
- Correct: Fix failures through feedback mechanisms like loop detection and context reinjection. When the agent goes wrong, the harness nudges it back.
Models have what LangChain calls “spiky intelligence.” They are brilliant at some things and surprisingly bad at others. A model might write elegant code but forget to run it. It might solve a complex algorithm but skip reading the task requirements carefully. The harness smooths out those spikes.
As LangChain’s Vivek Trivedy puts it: “The purpose of the harness engineer is to prepare and deliver context so agents can autonomously complete work.”
For Terminal Bench 2.0, the team deliberately compressed their optimization space to just three knobs:
- System prompts that guide how the agent plans, executes, and verifies
- Tools that give the agent capabilities like bash execution and filesystem access
- Middleware that hooks into model and tool calls to intercept and redirect behavior
Let’s examine each technique they applied, starting with the one that had the biggest impact.
Self-Verification Loops: Teaching Agents to Check Their Work
The single most impactful improvement came from self-verification. If you have built agents, you have probably seen this failure mode: the model writes a solution, glances at it, decides it looks reasonable, and moves on. It has a bias toward accepting its first plausible output. This is confirmation bias baked into the way these models work, and it kills benchmark scores.
LangChain attacked this with a four-stage verification cycle embedded in the system prompt:
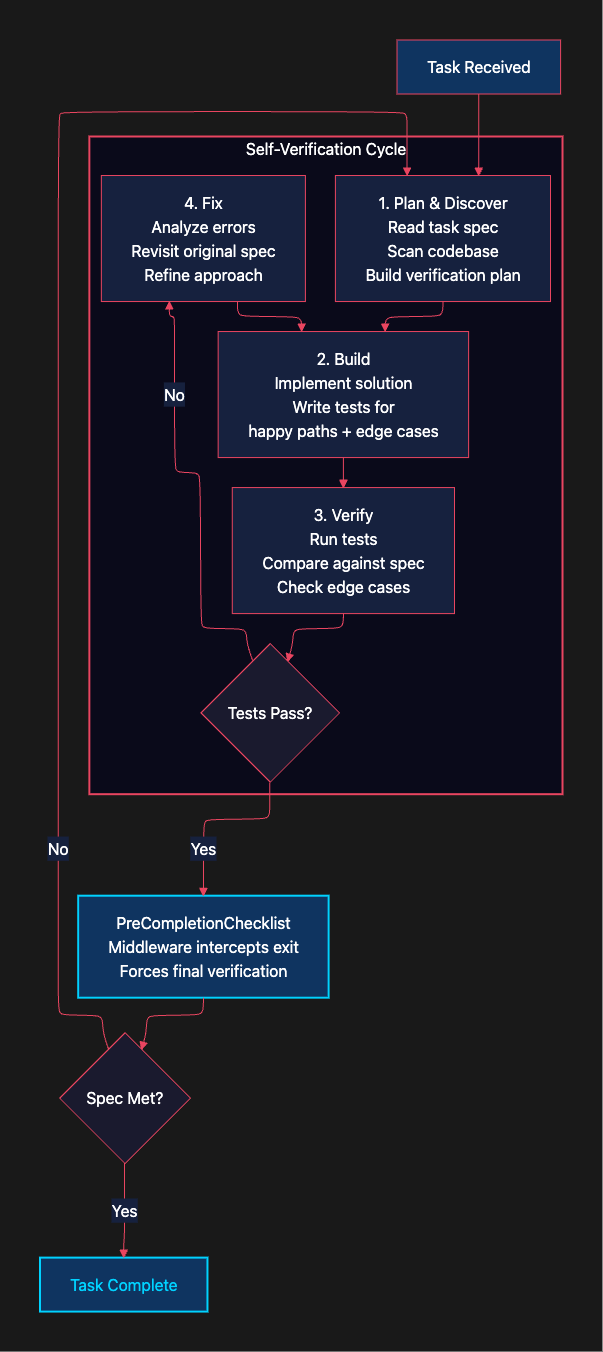
Stage 1: Plan and Discover. The agent reads the task specification, scans the codebase, and builds a verification plan before writing a single line of code. This alone eliminates a class of failures where agents dive straight into coding without understanding the problem. Think of it as the “measure twice, cut once” principle applied to AI coding.
Stage 2: Build. The agent implements the solution and writes tests covering both happy paths and edge cases. The emphasis on edge cases is deliberate. Without explicit instructions to test edge cases, agents tend to solve the obvious case and miss the tricky ones that Terminal Bench evaluates.
Stage 3: Verify. The agent runs those tests and compares results against the original task specification. This is where most improvements happen. Instead of relying on the model’s judgment about whether code “looks right,” the agent gets concrete pass/fail signals from actual test execution. Tests provide a feedback channel that is far more reliable than the model’s own assessment.
Stage 4: Fix. When tests fail, the agent analyzes the errors and revisits the original specification rather than just tweaking the failing code. This distinction matters. Tweaking code without revisiting the spec leads to patches that fix symptoms without addressing root causes.
The key enforcement mechanism is the PreCompletionChecklistMiddleware. This middleware intercepts the agent every time it tries to exit, forcing it through a final verification pass:
class PreCompletionChecklistMiddleware(Middleware):
"""Intercepts agent exit to force verification against task spec."""
def __init__(self, checklist_items: list[str] = None):
self.checklist_items = checklist_items or [
"Have you read the complete task specification?",
"Did you run all tests and verify they pass?",
"Have you checked edge cases beyond the happy path?",
"Does your solution match the exact file paths in the spec?",
"Did you verify output format matches expected format?",
]
async def on_model_call(
self, state: AgentState, is_exit: bool
) -> MiddlewareResult:
if not is_exit:
return MiddlewareResult(continue_execution=True)
# Agent is trying to exit -- inject verification prompt
checklist = "\\n".join(
f"- [ ] {item}" for item in self.checklist_items
)
verification_prompt = (
"STOP. Before completing this task, verify each item:\\n"
f"{checklist}\\n\\n"
"Run any necessary tests to confirm. "
"If any item fails, fix it before exiting."
)
return MiddlewareResult(
continue_execution=True,
inject_message=verification_prompt,
reset_exit=True, # Prevents exit, forces another loop
)The team calls this the “Ralph Loop” pattern, named after the Simpsons character who cheerfully announces “I’m in danger.” The agent thinks it is done, but the middleware sends it back. The name is whimsical, but the pattern is serious. It directly counters the model’s bias toward premature completion.
There are many frameworks that provide these sorts of checks for Claude Code, OpenCode, etc. For example, Superpowers is plan driven and TDD driven to the extreme that code can’t exist unless the plan and the test to test that code exists first. GSD also does a lot to enforce strict compliance and standards to the plan and GSD 2 goes even further. The whole spec driven movement is a nod in this direction but with varies degrees of looping and validation. When you enforce validation and feedback loops with specs and tests, you enforce this loop pattern.
Why this works: The verification loop transforms the agent’s interaction with its own output from a single pass (“write it and ship it”) into an iterative refinement process (“write it, test it, fix it, verify it again”). This mirrors how experienced developers actually work. Nobody ships code without running the tests.
Loop Detection: Breaking the Doom Loop
Self-verification pushes agents to keep iterating until they get it right. But that creates a new risk: what happens when the agent is stuck on a fundamentally wrong approach?
LangChain calls this the “doom loop.” The agent edits the same file ten or more times, making minor variations of the same broken strategy, never stepping back to reconsider. It is the coding equivalent of trying to force a puzzle piece into the wrong slot by rotating it slightly each time.
The LoopDetectionMiddleware addresses this by tracking per-file edit counts through tool call hooks:
class LoopDetectionMiddleware(Middleware):
"""Detects repetitive editing patterns and injects course corrections."""
def __init__(self, max_edits_per_file: int = 5):
self.max_edits = max_edits_per_file
self.edit_counts: dict[str, int] = defaultdict(int)
async def on_tool_call(
self, state: AgentState, tool_call: ToolCall
) -> MiddlewareResult:
if tool_call.name in ("edit_file", "write_file"):
file_path = tool_call.args.get("path", "")
self.edit_counts[file_path] += 1
if self.edit_counts[file_path] >= self.max_edits:
return MiddlewareResult(
continue_execution=True,
inject_message=(
f"You have edited {file_path} "
f"{self.edit_counts[file_path]} times. "
"Step back and reconsider your approach. "
"Review the original task specification."
),
)
return MiddlewareResult(continue_execution=True)Notice what this middleware does not do: it does not force the agent to change course. It adds a nudge at exactly the moment when the agent is most likely to be stuck. This is an important design choice. Hard stops would break legitimate cases where a file genuinely needs many edits. A contextual nudge preserves the agent’s autonomy while providing the information it needs to make better decisions.
The productive tension: Self-verification and loop detection work in creative opposition. The verification loop pushes the agent to keep trying until tests pass. The loop detector prevents that persistence from becoming stubbornness. Together, they keep the agent in a zone where it iterates productively without spinning its wheels. Think of it as providing both accelerator and brake pedals. Neither alone is sufficient.
LangSmith Traces as a Feedback Signal
The techniques above improved the agent, but how did the team know which improvements to make? How do you systematically debug an autonomous agent that runs 89 different tasks in isolated containers?
This is where LangSmith traces became the backbone of the development process.
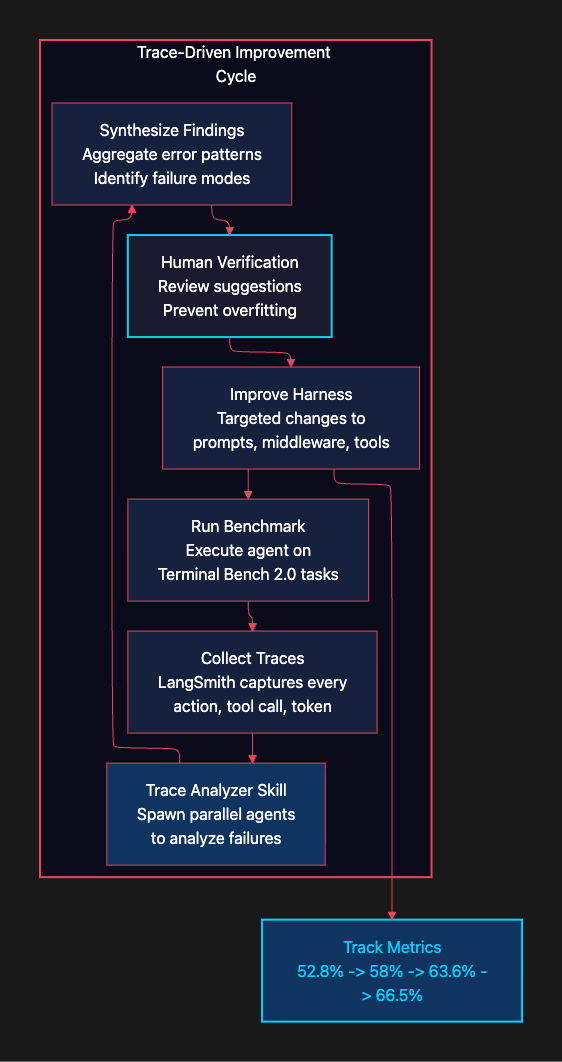
Every agent run generates comprehensive traces in LangSmith: every tool call, every token generated, latency measurements, cost metrics. The team built what they call the “Trace Analyzer Skill,” an agentic workflow that turns those traces into actionable improvements.
Here is the key insight behind the Trace Analyzer: instead of manually reviewing dozens of failed runs, the team used agents to analyze agent failures. The workflow fetches failed traces from LangSmith, spawns parallel analysis agents to examine different failures simultaneously, and then synthesizes the findings into targeted harness changes:
async def analyze_failures(experiment_id: str):
"""Trace Analyzer Skill -- automated failure analysis."""
client = Client()
# Step 1: Fetch traces from failed tasks
failed_traces = [
t for t in client.list_runs(
project_name="terminal-bench-eval",
filter='eq(status, "error")',
execution_order=1,
)
if not t.outputs.get("success")
]
# Step 2: Spawn parallel analysis agents
analyses = await asyncio.gather(*[
create_agent(
model="gpt-5.2-codex",
system_prompt="Analyze this trace. Identify what went wrong, "
"which middleware could prevent it, and suggest "
"a specific harness modification.",
).run(format_trace(trace))
for trace in failed_traces
])
# Step 3: Synthesize into actionable improvements
return await create_agent(
model="gpt-5.2-codex",
system_prompt="Synthesize failure analyses into prioritized "
"harness improvements. Group by failure pattern.",
).run("\\n\\n".join(str(a) for a in analyses))Think of this as gradient boosting for harness engineering. Just as gradient boosting focuses the next weak learner on the examples the ensemble gets wrong, the Trace Analyzer focuses the next harness iteration on the tasks the agent fails. Each cycle targets the remaining weaknesses, producing steady incremental improvement.
The failure modes they discovered and systematically addressed tell a story about what agents struggle with:

- Reasoning errors: Agent misunderstood the problem → Fixed with better planning prompts with explicit spec-reading → Reduced planning failures
- Instruction blindness: Agent skipped parts of task spec → Fixed with spec-aware prompting highlighting every requirement → Caught missed requirements
- Missing verification: Agent never tested its output → Fixed with PreCompletionChecklistMiddleware → Largest single improvement
- Timeouts: Too much reasoning on every step → Fixed with reasoning sandwich strategy → Recovered 12.6 percentage points
- Myopic planning: Repeated broken approaches → Fixed with LoopDetectionMiddleware → Broke doom loops
One critical detail: human verification sits between the analyzer’s suggestions and actual harness changes. Without this check, the team found they could overfit their harness to the specific failure modes of one benchmark run, making it worse on new tasks. The human reviewer ensures changes generalize across the full task distribution. This is a pattern worth remembering: even when you automate analysis, keep a human in the loop for decisions that affect the system’s general behavior.
The Reasoning Sandwich
Speaking of timeouts, let’s look at one of the more creative optimizations: the “reasoning sandwich.”
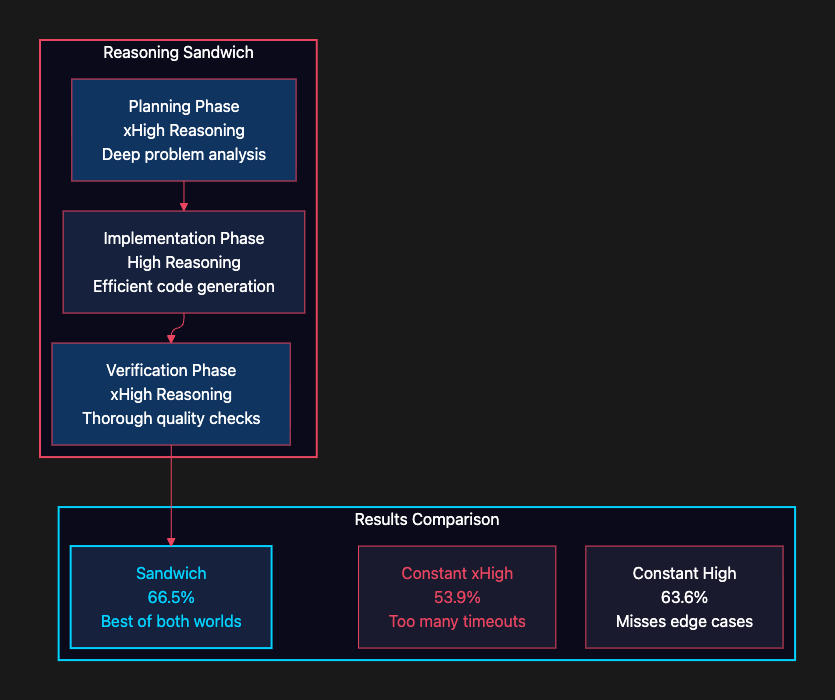
Modern reasoning models let you control how deeply they think. The naive approach is to crank reasoning to maximum for everything. The LangChain team tried this, and it backfired:

The team experimented with three different strategies for managing reasoning depth across agent execution. The first approach used constant xHigh reasoning: maximum cognitive effort at every step. This strategy achieved only 53.9% on the benchmark because the agent frequently ran into timeouts. While deep thinking is valuable, applying it uniformly consumed too much time budget, leaving tasks incomplete.
The second approach dialed back to constant High reasoning across all phases. This moderate level of cognitive effort improved performance significantly to 63.6% by avoiding timeouts. However, this strategy had its own weakness: it missed edge cases and subtle bugs that required deeper analysis to catch.
The winning strategy was the reasoning sandwich, which dynamically adjusts reasoning depth based on task phase. It uses xHigh reasoning during planning to deeply understand the problem, switches to High reasoning during implementation for efficient code generation, then returns to xHigh reasoning during verification to catch subtle issues. This adaptive approach achieved 66.5%: the best of both worlds. By allocating deep thinking strategically rather than uniformly, the sandwich strategy avoided timeouts while still catching the edge cases that moderate reasoning alone would miss.
The insight is elegant: not all phases of a coding task need the same depth of thought. Planning benefits from deep analysis because understanding the problem correctly is worth the time investment. Implementation can run at moderate reasoning because the plan already provides direction. Verification needs deep reasoning again because catching subtle bugs requires the same careful attention as understanding the problem initially.
The ReasoningSandwichMiddleware implements this by detecting the current task phase and adjusting the model's reasoning effort accordingly:
class ReasoningSandwichMiddleware(Middleware):
"""Adjusts reasoning depth based on task phase."""
PHASE_REASONING = {
"planning": "xhigh", # Deep analysis of the problem
"implementation": "high", # Efficient code generation
"verification": "xhigh", # Thorough quality checks
}
async def on_model_call(
self, state: AgentState, is_exit: bool
) -> MiddlewareResult:
phase = self._detect_phase(state)
reasoning_level = self.PHASE_REASONING.get(phase, "high")
return MiddlewareResult(
continue_execution=True,
model_kwargs={"reasoning_effort": reasoning_level},
)The 12.6-point gap between constant xHigh (53.9%) and the sandwich (66.5%) is remarkable. It means that thinking less during implementation actually improved results, because the agent had time budget left for the verification phase where deep thinking matters most. This is a lesson that applies beyond coding agents: strategic allocation of compute is more effective than brute-force maximum compute.
Context Engineering: Onboarding Your Agent
The final piece of the puzzle is environment onboarding. The LocalContextMiddleware runs when the agent starts up and does something deceptively simple: it maps the working environment before the agent sees its first task.
class LocalContextMiddleware(Middleware):
"""Onboards the agent by mapping its execution environment."""
async def on_agent_start(self, state: AgentState) -> MiddlewareResult:
dir_structure = await self._map_directory(state.working_dir)
tools_info = await self._discover_tools(state)
context = (
f"## Working Environment\\n"
f"**Current directory**: {state.working_dir}\\n\\n"
f"### Directory Structure\\n{dir_structure}\\n\\n"
f"### Available Tools\\n{tools_info}\\n\\n"
f"Use this information to navigate efficiently. "
f"Do not waste time discovering what is already mapped."
)
return MiddlewareResult(
continue_execution=True,
inject_message=context,
)Think of this as onboarding a new developer. You would not throw a new hire at a codebase without telling them where things are, what tools are available, or how the project is structured. The middleware gives the agent the same orientation.
Without context engineering, agents waste tool calls on discovery. They run ls in every directory, try to locate Python by running which python and which python3 and checking PATH entries. Sometimes they get confused by unexpected directory structures and go down rabbit holes that consume their time budget. With proactive context delivery, they start productive work immediately.
This connects directly to the concept we explored in Part 5 of this series: context is not just about what information the agent has, but about when and how it receives that information. Front-loading environment context eliminates an entire category of early-task failures.
Putting It All Together: The Middleware Pipeline
All four middleware components compose into a single pipeline that processes every agent interaction:

Here is how the full pipeline comes together in code:
from deepagents import create_cli_agent
agent = create_cli_agent(
model="gpt-5.2-codex",
middleware=[
LocalContextMiddleware(),
LoopDetectionMiddleware(max_edits_per_file=5),
ReasoningSandwichMiddleware(),
PreCompletionChecklistMiddleware(
checklist_items=[
"Read the complete task specification",
"Run all tests and verify they pass",
"Check edge cases beyond the happy path",
"Verify output format matches expected format",
"Confirm file paths match the spec exactly",
]
),
],
tools=[bash_tool, edit_file, read_file, write_file, ls_tool],
sandbox=HarborSandbox(provider="daytona"),
)Each middleware is independent and composable. You can add or remove layers without breaking the others. This modularity is what makes the approach practical for production use. You do not need to adopt the entire pipeline at once.
Lessons for Your Agents
The LangChain team distilled their experience into principles that apply far beyond Terminal Bench. Here are five you can act on today:
1. Verification beats generation. Investing in test execution and spec checking produces more improvement than better prompts or more powerful models. If your agent does not verify its work, that is your single highest-leverage improvement. Add a verification step before you try anything else.
2. Detect and break loops. Agents get stuck more often than you think. Simple heuristics like tracking edit counts per file can identify stuck agents before they waste your compute budget. Use a nudge, not a hard stop, to preserve the agent’s autonomy while redirecting its effort.
3. Trace everything, then use agents to analyze the traces. You cannot improve what you cannot see. Comprehensive tracing is not overhead. It is the feedback signal that makes systematic improvement possible. Using agents to analyze agent failures is a force multiplier that turns hours of manual review into minutes of automated analysis.
4. Allocate reasoning strategically. Not every step needs maximum compute. The reasoning sandwich (deep for planning and verification, efficient for execution) outperformed constant maximum reasoning by 12.6 percentage points. Think of reasoning compute as a budget to allocate, not a dial to crank.
5. Onboard your agent like a new hire. Proactive context delivery eliminates an entire class of discovery errors. Map the environment, locate tools, and inject structure before the agent starts working. Front-load the information your agent will need rather than making it discover everything on its own.
For teams ready to implement progressively:
- Level 1 (1–2 hours): Add a verification step to your agent’s system prompt. Instruct it to run tests before completing any task. Track basic metrics with LangSmith or a similar observability tool.
- Level 2 (1–2 days): Implement loop detection middleware. Set up comprehensive tracing for every agent run. Create an AGENTS.md file in your repositories to give agents project context from the start.
- Level 3 (1–2 weeks): Build a trace analyzer workflow that automatically identifies failure patterns. Implement the reasoning sandwich for compute allocation. Add environment onboarding middleware. Version your harness alongside your code.
Conclusion
LangChain’s jump from Top 30 to Top 5 on Terminal Bench 2.0 is a proof point for a bigger idea: the infrastructure around a model matters as much as the model itself. In a world where everyone has access to the same foundation models, harness engineering is the differentiator.
The techniques in this article are not theoretical. They are battle-tested patterns extracted from a real benchmark competition, validated by a 13.7 percentage point improvement that came entirely from systems engineering. No model change. No fine-tuning. No magic. Just disciplined engineering of the systems that surround the model.
As models continue to improve, some of these guardrails will become unnecessary. Models will learn to verify their own work, manage their own context windows, and avoid doom loops on their own. LangChain themselves position these interventions as temporary measures that will become obsolete as models mature. But that day is not today. Today, the agent that wins is the one with the better harness.
Build yours.
Sources:
- Improving Deep Agents with Harness Engineering — LangChain Blog
- The Anatomy of an Agent Harness — LangChain Blog
- Evaluating Deep Agents CLI on Terminal Bench 2.0 — LangChain Blog
- Terminal Bench 2.0 Leaderboard — tbench.ai
- Harness Engineering: Complete Guide — NxCode
- Harness Engineering for Agentic Coding Systems — ZenML
LangChain DeepAgent Series: From Theory to Practice
This five-part series traced the full arc of the deep agent revolution, from identifying the problem to validating the solution in production.
Article 1: The Shift from Shallow to Deep established the problem. Shallow ReAct agents work brilliantly for simple, short-horizon tasks: look up a fact, run a query, return a result. But they break down on complex, multi-step problems. Context windows overflow. The agent loses sight of its original goal. There is no way to delegate specialized work. The shift from shallow to deep required four architectural pillars: extreme context engineering, planning tools, subagent spawning, and persistent file system access.
Article 2: Open-Source vs. Proprietary examined the tension between approaches. Claude Code proved that deep agent architecture works at scale. But its proprietary nature limited who could benefit. Deep Agents brought those same patterns to the open-source ecosystem, with trade-offs: more flexibility and transparency, but requiring more assembly and tuning. The convergence of these approaches created a healthier ecosystem where proprietary tools push innovation and open-source implementations make that innovation accessible.
Article 3: The Middleware Engine went under the hood. LangGraph provides the durable runtime that makes deep agents possible: state management, checkpointing, error recovery, and middleware hooks. The middleware system enables dynamic prompt injection, human-in-the-loop approval workflows, and model routing. Without this engine, deep agents would be fragile prototypes. With it, they are production infrastructure.
Article 4: Context Management and Security tackled the hardest operational challenges. As agents handle longer tasks, their context windows fill up. Deep Agents solve this with conversation history summarization, large tool result eviction, and filesystem-based context offloading. On the security front, runtime context injection prevents unauthorized data access, and the middleware layer enables PII masking, output filtering, and approval gates for sensitive operations.
Article 5: Real-World Use Cases (this article) brought it all together with evidence. The CLI puts the complete architecture in a developer’s hands with a single install command. Deep research, software engineering, and incident analysis demonstrate that the theory works in practice. And the market adoption confirms that the developer community agrees: over 10,500 stars, 62 contributors, and integration into LangChain’s three-library stack.
Article 6: The power of harness engineering. LangChain’s DeepAgent coding agent improved its performance from 52.8% to 66.5% on Terminal Bench 2.0 through harness engineering techniques, including self-verification loops, loop detection middleware, and LangSmith traces. The focus was on optimizing the infrastructure around the model rather than changing the model itself. Key strategies included a structured verification process, context onboarding, and strategic reasoning depth allocation, which collectively enhanced the agent’s ability to handle complex tasks effectively.
About the Author
Rick Hightower is a technology executive and data engineer who led ML/AI development at a Fortune 100 financial services company. He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world’s largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI.
Related Articles
If you found this exploration of LangChain Deep Agents valuable, you might also enjoy these related articles that dive deeper into the topics of agent architecture, context engineering, and harness engineering:
LangChain Deep Agent Series
- The Agent Framework Landscape: LangChain Deep Agents vs. Claude Agent SDK — Comparing architectures and capabilities of leading AI agent frameworks
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security — A deep-dive into how Agent Brain, Agent Skills, and Agent RuleZ work together inside a LangChain agent architecture to deliver memory, security, and reusable workflows
- Under the Hood: Middleware, Sub-Agents, and Deep Agent LangGraph Orchestration — Explores how middleware, sub-agents, and LangGraph work together as the runtime layer the harness operates within
- Introduction to LangChain Deep Agents and the Shift to “Agent 2.0” — Frames the architectural shift from simple tool-using chatbots to Agent 2.0 systems with persistent memory, hierarchical orchestration, and harness-controlled execution
Context and Harness Engineering
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS — Introduces the conceptual distinction between context engineering and harness engineering using the CPU/OS analogy
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage — Navigating the challenges of AI code generation and implementing harness engineering to ensure reliability and safety
- Mastering Claude Code’s /btw, /fork, and /rewind: The Context Hygiene Toolkit — Learn how to use Claude Code’s context management commands to eliminate context pollution and optimize your AI coding workflow
- Context Engineering: Agents — Injecting the Right Rules at the Right Moment — Covers the mechanics of dynamic rule injection — how and when architectural constraints are delivered to an agent during execution, not just at startup
Agent Skills and Automation
- Claude Code Agent Skills 2.0: From Custom Instructions to Programmable Agents — Explains the evolution of agent skills from simple slash-command instructions to fully programmable, multi-step workflows with validation and feedback loops
- Claude Code Rules: Stop Stuffing Everything into One CLAUDE.md — Provides a practical guide to structuring agent rules across multiple files rather than a single monolithic rules file — the approach that Agent RuleZ formalizes
- The End of Manual Agent Skill Invocation: Event-Driven AI Agents — Describes how agent skills can be triggered automatically by events rather than manually, eliminating a major source of inconsistency in multi-step agentic workflows
- Put Claude on Autopilot: Scheduled Tasks with /loop and /schedule built-in Skills — Demonstrates built-in Agent Skills for scheduling and looping — concrete examples of how harness-managed skills enable autonomous, long-running agent operation
Memory and Governance
- Claude Code’s Automatic Memory: No More Re-Explaining Your Project — Covers the automatic memory capability that ships with Claude Code and how it maintains context across sessions
- From Approval Hell to Just Do It: How Agent Skills Fork Governed Sub-Agents in Claude Code 2.1 — Shows how Agent Skills combined with policy islands (forked sub-agents with pre-declared permissions) eliminate approval fatigue while maintaining governance
No comments:
Post a Comment